Redneck Cloud Computing
Every now and then I wonder what decisions might be different if I had access to a cloud of machines dedicated to baking game assets or solving other highly parallelizable tasks. So I started looking into what options were available to someone wanting to distribute a ton of work over many machines. I found lots of options but all of them suffered from one or more of these problems,
- Specialized language
- Specialized framework (tied to language)
- Specialized operating system
- New versions would require manual deployment
- Non-commercial license
I wanted a solution that didn’t require a specialized framework or language because chances are I would find something I wanted to distribute that I didn’t want to completely rewrite. No specialized OS, I want to be able to slave any unused windows machine in the office (dedicated farms are really expensive). Also if I need to perform new operations or fix a bug, I don’t want to reinstall / deploy new versions to everyone’s machine.
So I decided to roll my own solution and share the design. I’ll share the finished version of the software once I’ve completed it.
Let’s start with a usecase. I have an executable and a pile of data on disk that I would like to distribute over a ton of machines. I was able to quickly modify the existing program to have a command line option that allowed it to process a range of the data on disk instead of all of it. How do I distribute this work over multiple machines so that I process all the data on disk?
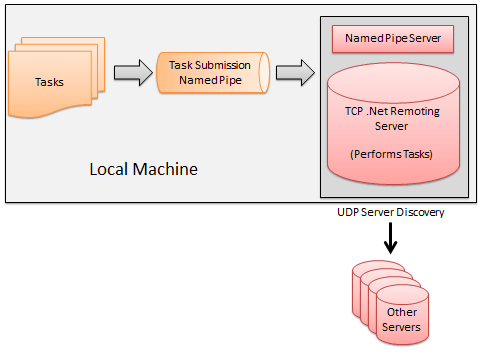
Each time we execute the program with some amount of data to be processed, let’s call that a task. Each task will be processed by some machine in the cloud. To submit the tasks, we will need some common / cross language mechanism of communication. I chose named pipes just because they are easy to use on windows.
To submit tasks to the named pipe, we could either write a simple reusable program that reads task descriptions from a file and submits them to the named pipe, or we could wrap the named pipe communication in a C++ library so that C++ and C# (P-Invoke) could both reuse the logic inside of many various tools (including the generic reusable program that reads task descriptions from files or std::in).
Each machine has a single server running on it. I chose to write the server in C#, but it’s a blackbox as far as your tasks are concerned so you could use something different if you wanted.
Once the server receives the task description via the named pipe it looks at the list of servers it knows about. The serves are detected using a simple UDP broadcast.
Using .Net remoting I then connect to each one of these machines to see what it can offer me.
Now each of these machines could have who knows what installed on them, and you’re about to transfer and run an exe that may have requirements, like .Net 4.0. So each task needs to contain a list of requirements. For now, I’ve got them scoped to 3 things, defined environment variables, registry key/values and .Net version. You could probably drop the .Net version if you just always keep your server written using the latest version so it’s a prerequisite for any machine on your network.
Now I can try and reserve a slot on the machine, if I fail to reserve a slot because of a race condition I move onto the next server.
Having reserved a slot (some machines that are idle or dedicated may have multiple slots), I need to transfer the executable and all the data files listed inside the task description that are claimed to be needed by the task.
I tell the remote server to then begin running the task in a new thread and I continue looking for empty slots in the cloud to submit tasks to.
After I discover that a task has finished, everything that is different in the remote folder where the task was dumped and subsequently executed is then transferred back to the local machine that submitted the task.
The named pipe that was used to submit one or more tasks remains open the whole time and is notified after each task is finished and the data successfully transferred back to the host machine.
So that’s the design in a nutshell. It’s not a solution designed to solve every distributed computing problem, but I like that it solves a very common pattern of problems I see fairly often in a non-intrusive manner.
I haven’t nailed down yet the best way to prevent the system from being abused by a malicious user. However, I suspect having a SQL server with the list of MD5 hashes of the executables that are approved for deployment is one idea I’ve been toying with.
Here’s a simple diagram to help explain the task submission process. Because who doesn’t love diagrams.